简介
这篇文章关注对event extraction提供标注数据的方法。传统的hand-labeled的训练数据非常昂贵,并且event覆盖的非常有限。这使得一些supervised的方法很难去抽取大规模的event来进行KBP(knowledge base population)。
我们知道,关系抽取中可以用远程监督的方法来自动标注数据,一种想法就是可以不可以把这种方法扩展到event extraction。然而这样会有两个问题:
- 第一个问题
事件抽取的目标是检测事件实例的类型并抽取其argument及role,即$(event \, instance, event \, type;
role_1, argument_1; role_2, argument_2; …; role_n,
argument_n)$在Freebase等knowledge base中,事件的表示如图所示:
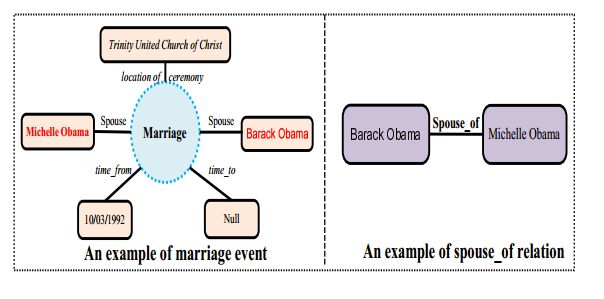
矩形表示事件实例的arguments,连接arguments和事件实例的每条边都表示arguments的role,这样看好像是可以使用远程监督自动标注数据,但是在通常的事件抽取中,一个事件实例通常是使用trigger word来表示的,但在现有的knowledge base 中并不存在事件的triggers。为了解决这个问题,所以需要在使用远程监督前找到事件的trigger word。
- 第二个问题
一个句子实际上并不能够包含某一事件的所有参数,简单地使用知识库中的所有参数在句子中进行标记,将只有很少的句子满足条件,因此作者选择了几个具有代表性的参数来代表事件。
方法
作者提出了一个利用world knowledge(Freebase)和linguistic knowledge(FrameNet)来自动标注event extraction所需要的数据的方法。这个方法能够探测到每一个event type的key argument和trigger word,然后用它们来从文本中标注event。
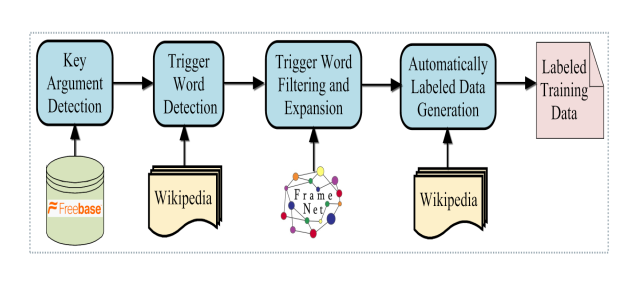
方法主要分为4步:
Key Argument Detection
使用Key Rate(KR) 来衡量某一事件类型中各个参数的重要性,然后在Freebase中计算每个事件类型中所有argument的KR,然后选择前$K$大个作为key argument。
计算KR公式如下:
$$ K R_{i j}=R S_{i j} * E R_{i} $$
其中,RS为角色显著性(Role Saliency)。区分同一类型中一个事件实例和另一个事件实例。
$$R S_{i j}=\frac{\operatorname{Count}\left(A_{i}, E T_{j}\right)}{\operatorname{Count}\left(E T_{j}\right)} $$
分子:$eventType_j$所有实例中出现$Argument_i$的数量,
分母:$eventType_j$实例的总数。
某一参数在某一特定类型中出现越多,说明RS越大,越能代表这个类型的特点。
ER为事件相关性(Event Relevance)。区分不同事件类型。
$$E R_{i}=\log \frac{\operatorname{Sum}(E T)}{1+\operatorname{Count}(E T C i)}$$
分子:所有事件类型总数,
分母:出现过$Argument_i$的事件类型的数量。
如果一个参数在所有事件类型中都出现,那么则这个参数区分性不高,具有较低的ER。Trigger Word Detection
包含所有key argument的句子更有可能表示Freebase中对应的事件实例,首先使用key arguments在Wikipeida中筛选标注句子,然后使用这些句子来进行触发词检测。
这里有一个假设:出现在这些句子中动词往往倾向于触发这类事件。
动词在同一种类型的事件中出现很多次,说明有可能为此事件的触发词,而如果动词在不同类型中均出现,则为触发词的概率很小。作者使用Trigger Rate (TR)来衡量动词是trigger word的概率,最后选择具有较高TR的动词作为对应事件类型的trigger word。
计算TR公式如下:
$$
T R_{i j}=T C F_{i j} * T E T F_{i}
$$
其中,Trigger Candidate Frequency (TCF)动词在同一类型事件中出现的频率。
$$
T C F_{i j}=\frac{\operatorname{Count}\left(V_{i}, E T S_{j}\right)}{\operatorname{Count}\left(E T S_{j}\right)}
$$
分子:$j$类型中包含动词$i$的句子数量,
分母:$j$类型中的句子数量。
Trigger Event Type Frequency (TETF)衡量了动词在不同事件类型中的出现频率。
$$
T E T F_{i}=\log \frac{\operatorname{Sum}(E T)}{1+\operatorname{Count}\left(E T I_{i}\right)}
$$
分子:所有事件类型总数,
分母:句子中出现过动词$i$的事件类型数量。Trigger Word Filtering and Expansion
上面得到的初始触发词中只有动词,然而像marriage这种名词也是可以作为触发词的,又因为句子中名词数量远多于动词,所以使用像动词一样的TR方法不现实。故采用FrameNet来过滤和扩展trigger words。使用词嵌入技术,来衡量词的相似性,将Freebase的事件映射到FrameNet的frame,然后过滤掉在FrameNet中没有对应映射的动词,在动词映射到的frame中使用具有高度置信度的名词来扩展触发词。Automatically labeled data generation
包含某一事件类型所有key argument和任何trigger word的句子在某种意义上可表示一个事件,这里使用Soft Distant Supervision的方法在Wikipedia中重新筛选和标注句子。从而得到了自动标注的数据。
实验
人工对自动标注的数据进行检查,标注正确就标个y,反之标n。三个人进行检查,最终结果投票决定,结果显示自动标注的数据质量很高。
将自动标注的数据与ACE数据结合,进行检查,实验结果显示大规模自动标注的数据与精心设计的人工标注的数据效果相当。所提出的自动标注的数据能够与人工标注的数据结合用来提高利用这些数据训练的模型的性能。
另外,为了缓解自动标注过程中远程监督带来的误标注问题,文中提到了一种多实例学习(Multi-instance Learning)的方法,将多个句子看作一个包,也带来了事件抽取效果上的提升。
Reference
Automatically Labeled Data Generation for Large Scale Event Extraction