np.meshgrid()
从坐标向量返回坐标矩阵,生成网格数据。
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22x = np.arange(-2,2)
y = np.arange(0,3)#生成一位数组,其实也就是向量
x
Out[31]: array([-2, -1, 0, 1])
y
Out[32]: array([0, 1, 2])
z,s = np.meshgrid(x,y)#将两个一维数组变为二维矩阵
z
Out[36]:
array([[-2, -1, 0, 1],
[-2, -1, 0, 1],
[-2, -1, 0, 1]])
s
Out[37]:
array([[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2]])
z 和 s 就构成了一个坐标矩阵 (-2,0),(-1,0),(0,0),(1,0),(-2,1),(-1,1),(0,1) … (2,0),(2,1)。实际上就是一个网格。
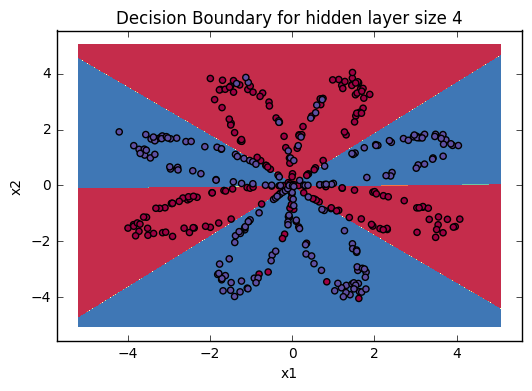
用matplotlib画等高线图,contourf可以填充等高线之间的空隙颜色,呈现出区域的分划状,所以很多分类机器学习模型的可视化常会借助其展现。
核心函数是plt.contourf(),输入的参数是x,y对应的网格数据以及此网格对应的高度值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 计算x,y坐标对应的高度值
def f(x, y):
return (1-x/2+x**5+y**3) * np.exp(-x**2-y**2)
# 生成x,y的数据
n = 256
x = np.linspace(-3, 3, n)
y = np.linspace(-3, 3, n)
# 把x,y数据生成mesh网格状的数据,因为等高线的显示是在网格的基础上添加上高度值
X, Y = np.meshgrid(x, y)
# 填充等高线
plt.contourf(X, Y, f(X, Y))
# 显示图表
plt.show()
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
cmap = plt.cm.Spectral 实现的功能是给label为1的点一种颜色,给label为0的点另一种颜色。
tips:
计算正确率的向量方法,np.dot()进行矩阵乘法,如果相同,则乘积和为1,反之为0。
1 | float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) |
有时为保证能重现结果,设置相同的seed,每次生成的随机数相同。
1 | np.random.seed(2) # we set up a seed so that your output matches ours although the initialization is random. |
公式
对于 $x^{(i)}$:
$$z^{[1] (i)} = W^{[1]} x^{(i)} + b^{[1] (i)}$$
$$a^{[1] (i)} = \tanh(z^{[1] (i)})$$
$$z^{[2] (i)} = W^{[2]} a^{[1] (i)} + b^{[2] (i)}$$
$$\hat{y}^{(i)} = a^{[2] (i)} = \sigma(z^{ [2] (i)})$$
$$y^{(i)}_{prediction} =
\begin{cases}
1& \hat{y}^{(i)} > 0.5 \\
0& \text{otherwise}
\end{cases}$$
使用下面公式计算损失 $J$ :
$$J = - \frac{1}{m} \sum\limits_{i = 0}^{m} \large\left(\small y^{(i)}\log\left(a^{[2] (i)}\right) + (1-y^{(i)})\log\left(1- a^{[2] (i)}\right) \large \right) \small $$
神经网络结构
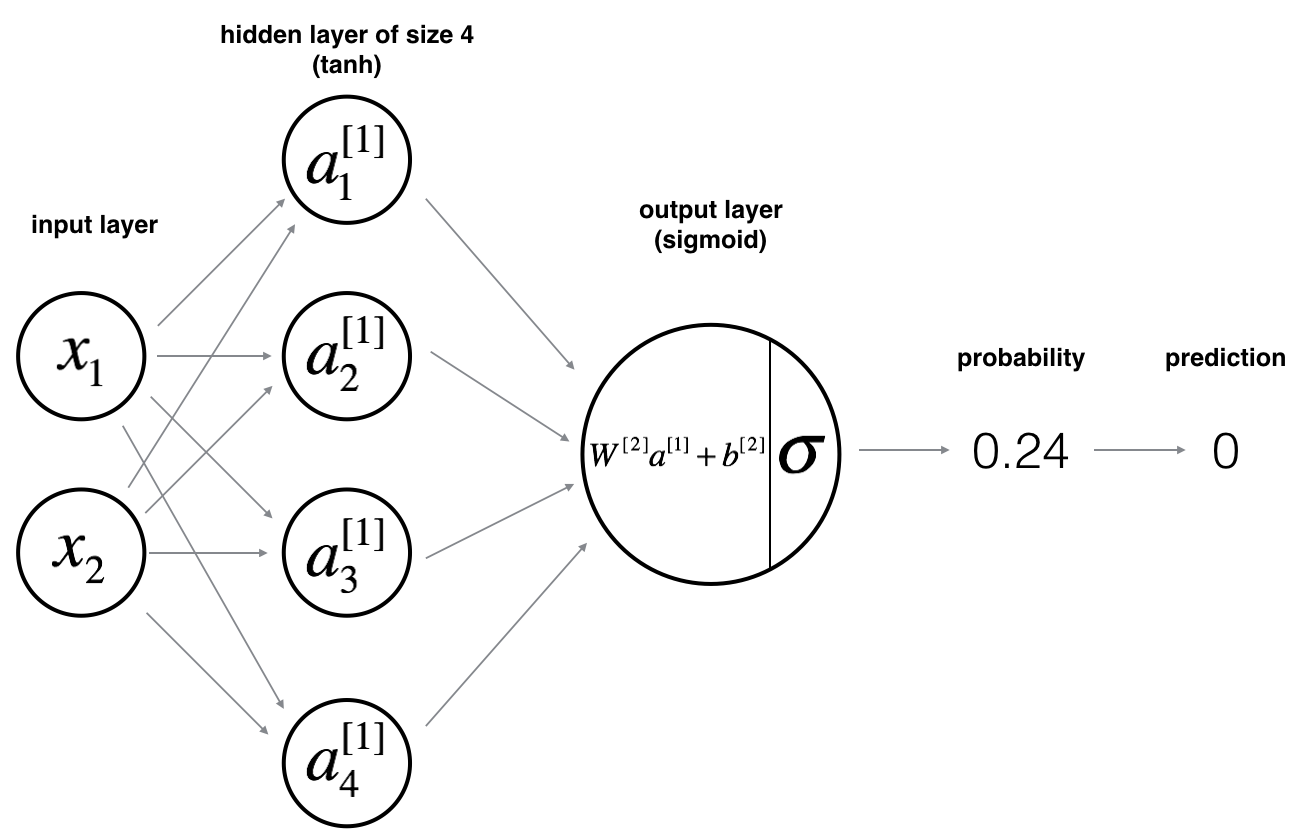
算法步骤
- 定义神经网络结构:输入单元数量、隐藏单元数量、输出单元数量。
1 | def layer_sizes(X, Y): |
- 初始化模型参数
1 | def initialize_parameters(n_x, n_h, n_y): |
- 实现前向传播
1 | def forward_propagation(X, parameters): |
- 计算损失函数
1 | def compute_cost(A2, Y, parameters): |
- 计算反向传播
1 | def backward_propagation(parameters, cache, X, Y): |
- 更新参数
1 | def update_parameters(parameters, grads, learning_rate = 1.2): |
- 将上述几步结合,实现最后的模型
1 | def nn_model(X, Y, n_h, num_iterations = 10000, print_cost=False): |
- 实现预测函数
1 | def predict(parameters, X): |
那么怎么调用我们实现的这个模型呢?
1 | parameters = nn_model(X, Y, n_h, num_iterations = 5000) |
其中,plot_decision_boundary是实现可视化的函数,其实现如下:
1 | def plot_decision_boundary(model, X, y): |
效果类似下图: